5 min read
Jan 8, 2026
The Architect’s Guide to AI Chart Abstraction
Executive Summary
Building a chart abstraction prototype with an LLM takes a weekend. Building a production-grade system that achieves >95% recall, survives a regulatory audit, and handles the "note bloat" of modern EHRs is a multi-year, high resource infrastructure commitment. If you are considering building this internally, this guide outlines the four non-negotiable pillars of a "Data Factory" required to move past the prototype phase and into production reality.
Introduction: The 80/20 Trap of Chart Abstraction
In healthcare AI, the first 80% of accuracy is deceptively easy. A well-constructed prompt and a modern foundation model can extract basic diagnoses with surprising speed.
However, in chart abstraction, value is generated at the margins. The final 15–20% of performance, identifying incremental diagnoses, flagging unsupported conditions, and resolving coding exclusions, is where the ROI lives. Reaching this level isn't only an AI problem; it is a systems engineering problem as well.
Before committing engineering resources to a "Build" strategy, your team must decide if they want to manage the model or the infrastructure required to achieve best-in-class performance.
Phase 1: The Build vs. Buy Framework
The first step is determining if the problem is Organization-Specific or General.
• Build Organization-Specific Systems: These are systems where competitive advantage comes from proprietary data or internal logic (e.g., your specific population health intervention triggers).
• Buy or Partner for General Systems: These are systems where correctness and reliability are the only metrics that matter, the problem shape is the same for everyone, and performance improves with broad exposure to data or scale.
Chart abstraction is a General Problem. The task definition (extracting ICD-10, HCC, or SNOMED codes) is identical across the industry. The variability comes from external sources, meaning providers, facility types, and EHR systems, not from your internal logic. And performance is critical due to the revenue implications. Building this internally means you are assuming the "Maintenance Tax" for a problem where performance matters but that doesn't differentiate your brand.
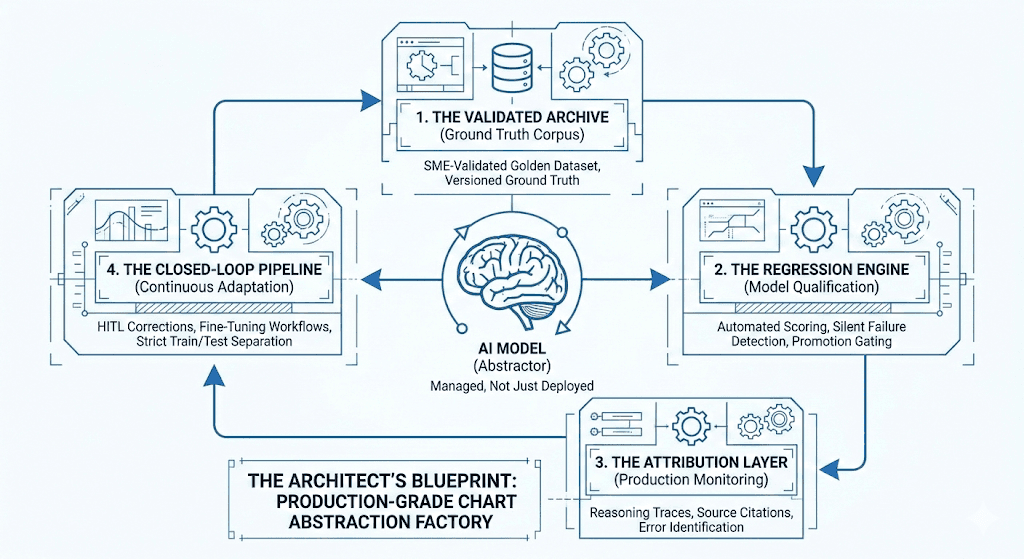
Phase 2: The Blueprint (The 4 Pillars of the Data Factory)
A production-grade system is more than a model; it is a Data Factory. If you are building this internally, your roadmap must include these four integrated components:
1. The Validated Archive (Ground Truth Corpus)
You cannot improve what you cannot measure. You will need a versioned, evolving datasets that serve as your "North Star", support a clear set of performance measures, and allow you to understand your model’s capabilities. This module should include:
Structured knowledge evaluations (ontology and rule quizzes)
Synthetic chart data with SME-validated ground truth (“Golden Dataset”)
Documented failure modes and edge cases
Augmented datasets from prior training cycles
With the key properties of:
Full SME-validation
No PHI (enables unrestricted retraining)
Versioned and periodically refreshed to maintain evaluation independence
The goal of this module is to provide a zero-PHI environment with realistic, validated data that allows for unrestricted model retraining and objective benchmarking.
2. The Testing Engine (Model Qualification)
Every foundation model has its own set of underlying capabilities. Moreover, every time a foundation model is updated or a prompt is tweaked, something else often breaks. Each base model or candidate release must be scored against the Archive data to ensure continually improving performance. This module includes:
Base model screening
Evaluates whether a foundation model possesses sufficient latent knowledge to support abstraction without excessive scaffolding.Candidate model evaluation
Scores trained variants against the Golden Dataset, enabling:Objective performance comparison
Regression detection
Promotion gating for production deployment
Without this layer, poor model decisions are made and and you become exposed to silent failures in production, where a model gets a new diagnosis right but loses an old one it previously handled correctly.
With this module you get objective promotion gating. No model goes live without a quantitative quality score.
3. The Observation Layer (Production Monitoring)
Once deployed, models must be observed, not just measured.
This module:
Overreads production outputs
Generates reasoning traces and source citations
Identifies systematic failure modes and ambiguous cases
Prioritizes samples for human review and retraining
This component is critical for improving performance where it actually matters. It locates failures in production and prioritizes the correct samples for human review.
4. The Training Loop (Continuous Adaptation)
The facts on the ground are constantly changing: Medical guidelines change. Coding sets update annually. As you develop experience, new edge cases will emerge that require correction or development. Your system cannot be static.
This module orchestrates:
Synthetic data generation to expand the Archive
Fine-tuning workflows
SME Human-in-the-loop labeling
Dataset publishing back into the Archive with strict train/test separation
It also supports customer-specific adaptations while preserving baseline performance guarantees. This module ensures that the system actually gets smarter and cheaper to operate with every chart it processes.
Phase 3: The Build Readiness Checklist
If you are still leaning toward "Build", ensure your leadership can answer "Yes" to the following:
1. SME Availability: Do we have 3–5 dedicated clinical SMEs who can spend 20+ hours a week validating "Golden Datasets" and diagnosing failure cases?
2. Engineering Opportunity Cost: Is building an abstraction factory more valuable than the next three features on our core product roadmap?
3. Data Exposure: Do we see enough document diversity (across dozens of EHRs and thousands of providers) to train a model that won't fail when it sees a new note format?
4. Long-Term Ownership: Are we prepared to own the maintenance of this system for the next 5–10 years as LLMs and coding regulations evolve?
Conclusion: Focus on the Outcomes, Not the Plumbing
For most organizations, the goal is not to "own an abstraction system", but to own the clinical and financial outcomes that abstraction enables.
We built our "Data Factory" so that our partners don't have to. We operate the Archive, the Testing Engine, and the Observation Layer at scale, processing millions of charts and absorbing the complexity of the last 20%.
If your team would rather focus on proprietary clinical interventions than building a regression framework for LLMs, let’s talk. We’ve already built the factory; you can just use the outputs.
Curious how HealthMC could help you? Let’s talk.











